Measuring Diversity in AD Research
An empirical investigation structured around the three dimensions of diversity identified in Part I, applied to Alzheimer's & Dementia(2025), the field's flagship journal.
Organising principle
The same framework that defines the problem in Part I organises this investigation. Each pillar addresses a distinct question, measured through a specific lens.
Who is studied?
Dataset citations as a direct proxy for which populations are examined in published AD research.
Does the literature treat sex as a biological variable?
Proportion of papers performing sex-aware analyses rather than treating sex as a covariate.
Is the infrastructure open, and the research team diverse?
Code/data sharing rates, geographic origin of labs, and gender composition of authorship.
2025 Pipeline Run: Headline Results
Alzheimer's & Dementia (Wiley, ISSN: 1552-5260) · 913 papers manually downloaded and screened
Repository hosting platforms (from extracted links)
Most frequently cited datasets
Three Sub-Repositories
31 AD datasets documented — the reference used for dataset mention scanning in Sub-repo 03.
github.com/KahinaBch/ad-dataset-catalogue ↗Neuroimaging atlases and harmonisation pipelines enabling multi-site pooling across diverse populations.
github.com/KahinaBch/ad-atlases-harmonisation ↗913 papers screened across all three pillars. Complete 2025 pipeline run with results and figures.
github.com/KahinaBch/ad-reproducibility-audit ↗The Pipeline (Sub-repo 03)
Alzheimer's & Dementia · 913 papers · 2025 · Adapted from Boudreau et al. (MRM)
Reproducibility defined
Computational reproducibility: the ability of an independent researcher to re-run the analyses underlying a published paper and obtain the same results, requiring shared code, shared data, and documentation. We use the presence of open-science indicators in published papers (GitHub links, data availability statements, OSF/Zenodo deposits) as a proxy measure. Each pipeline step is labelled with the pillar it addresses.
Full-text PDFs of Alzheimer's & Dementia articles were manually downloaded for 2025. Automated bulk download is not possible due to copyright restrictions. 913 PDFs were collected and organised into month folders by acceptance date.
⚠ Manual download is required for copyright compliance .
Each PDF is parsed to extract acceptance date; papers are sorted into month folders and compiled into an Excel workbook with one row per article. 2025: 913 rows.
Each PDF is scanned for platform names (github, osf, zenodo, dryad, figshare), sharing statements (code available, data available, openly available), and tool indicators (jupyter, notebook, open source). Repository links are extracted where present.
⚠ Hypothesis (Pillar 3): if sharing practices are improving, rates should increase over time. 2025: 88.7% keyword match, but only 9.4% contain an actual repository link.
Full text is scanned for: sex-stratified, sex differences, gender-specific, sex-disaggregated, sex-based analysis, female-specific, APOE sex interaction, menopause, hormonal influence, stratified by sex. Papers classified as 'sex-aware main focus' (keyword in title) or 'sex-aware consideration' (keyword in body only).
⚠ Hypothesis (Pillar 2): the proportion of AD papers explicitly treating sex as a biological variable is low, in tension with the ~65% female disease burden and the NIH mandate.
PDF text is scanned for names from the AD Dataset Catalogue, identifying which datasets, and therefore which populations, are most cited in published AD research.
⚠ Hypothesis (Pillar 1): a small number of North American/European cohorts (ADNI, NACC, UK Biobank) will dominate dataset citations, reflecting the geographic concentration of AD research.
Human validation of every keyword match: is this a genuine sharing statement or a false positive? Does the linked repository actually contain the code/data described? Validates False Positive?, Shared code?, Shared data? columns.
⚠ Critical: automated detection cannot distinguish 'available upon request' (not open) from 'code at github.com/...' (genuinely open).
First/last author names are retrieved via DOI and gender is inferred from names using the gender-guesser Python package (heuristic, name-based). Enables analysis of gender representation in AD research leadership, a structural dimension of Pillar 3 (researcher diversity as part of the open-science infrastructure question).
First-author affiliation country is extracted from PDF text (pdfminer + pycountry). Maps the geographic origin of the research teams producing published AD science, a structural dimension of Pillar 3. 2025: 99.1% of papers successfully attributed.
Sharing rates, platform breakdown, sex-keyword prevalence, country distributions, and dataset citation frequencies are computed.
All output figures generated (percentage/proportion based; one plot per file). Stored in plots/{year}/ and served directly from this repository.
Results: Three Pillars of Diversity
Figures served from ad-reproducibility-audit/plots/2025/.
Who is studied?
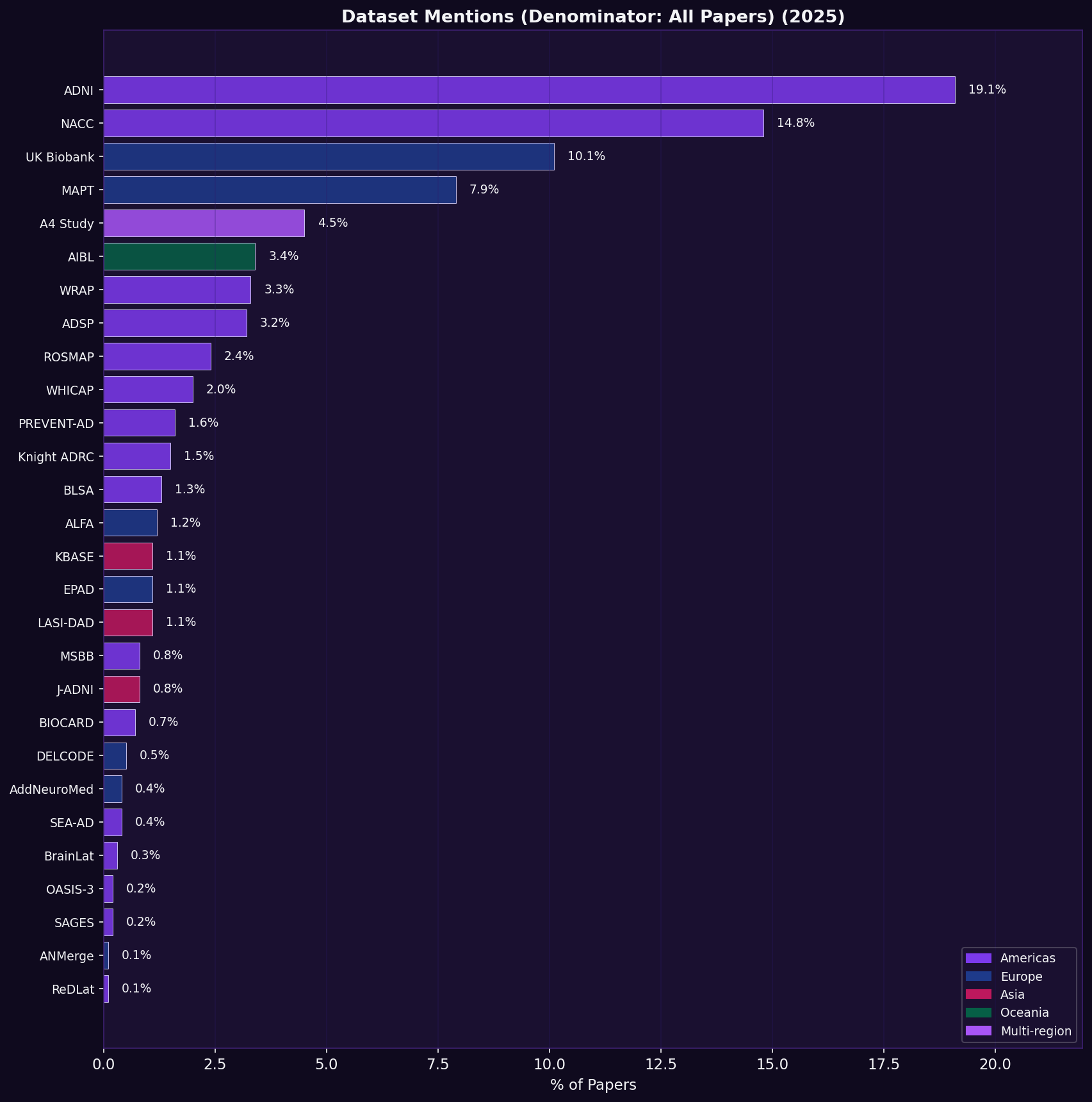
Finding: 482 of 913 papers (52.8%) cited at least one known dataset. The most frequently cited: ADNI (175 papers, 19.2%); NACC (136, 14.9%); UK Biobank (92, 10.1%). Bars are colour-coded by dataset geographic origin.
Why this matters: Dataset citations are a direct proxy for which populations are studied. A concentration in a handful of North American/European cohorts means that the findings published in the field's flagship journal overwhelmingly reflect a narrow slice of the world's at-risk population, limiting both scientific generalisability and equity in how results are applied globally.
Does the literature treat sex as a biological variable?
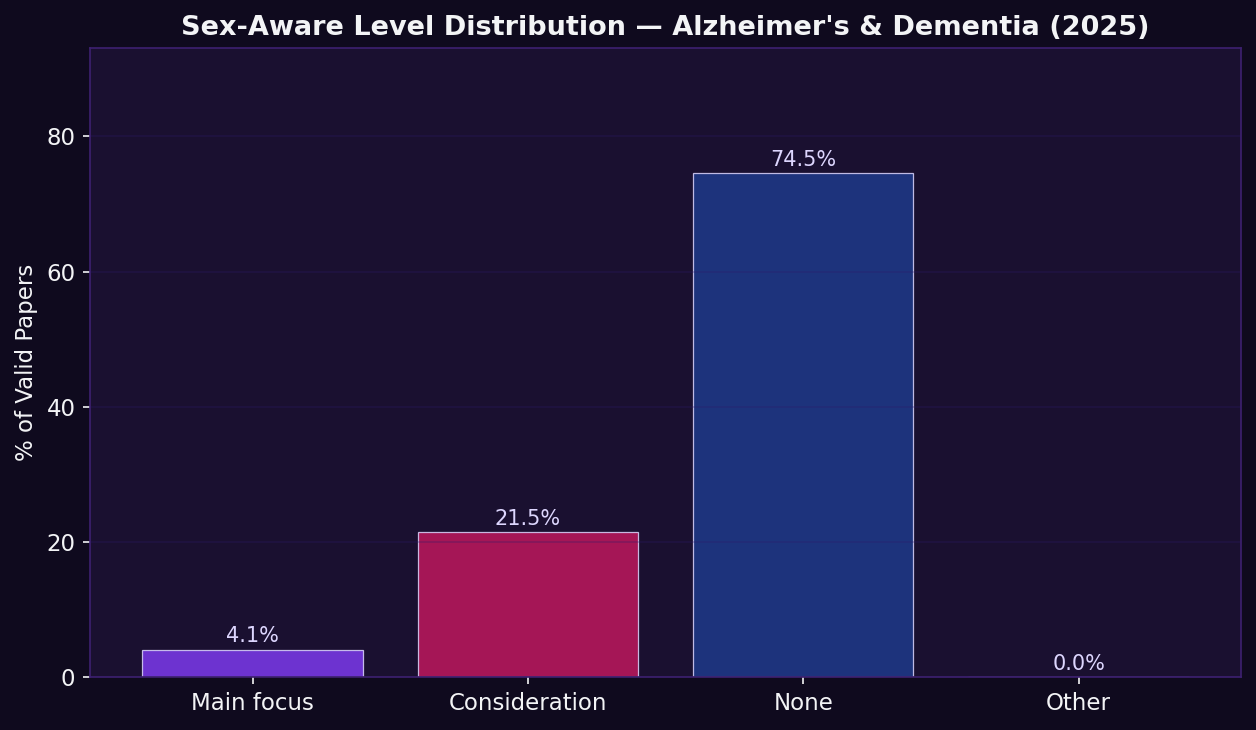
Finding: Out of 913 papers: 37 (4.1%) classified as 'sex-aware main focus' (keyword in title); 196 (21.5%) as 'sex-aware consideration' (keyword in body only); the remainder had no sex-specific keywords detected.
Why this matters: Only 4.1% of papers make sex a primary research focus, despite women accounting for two-thirds of the disease burden. This quantifies, for the first time in a systematic and reproducible way, the gap between the biological importance of sex in AD and its treatment in the published literature.
Is the infrastructure open, and the research team diverse?
Key finding: The gap between 88.7% keyword match and 9.4% genuine repository links is the core result of Pillar III. It reveals that the majority of open-science language in the AD literature is not backed by accessible repositories, distinguishing between the rhetoric of open science and its practice.
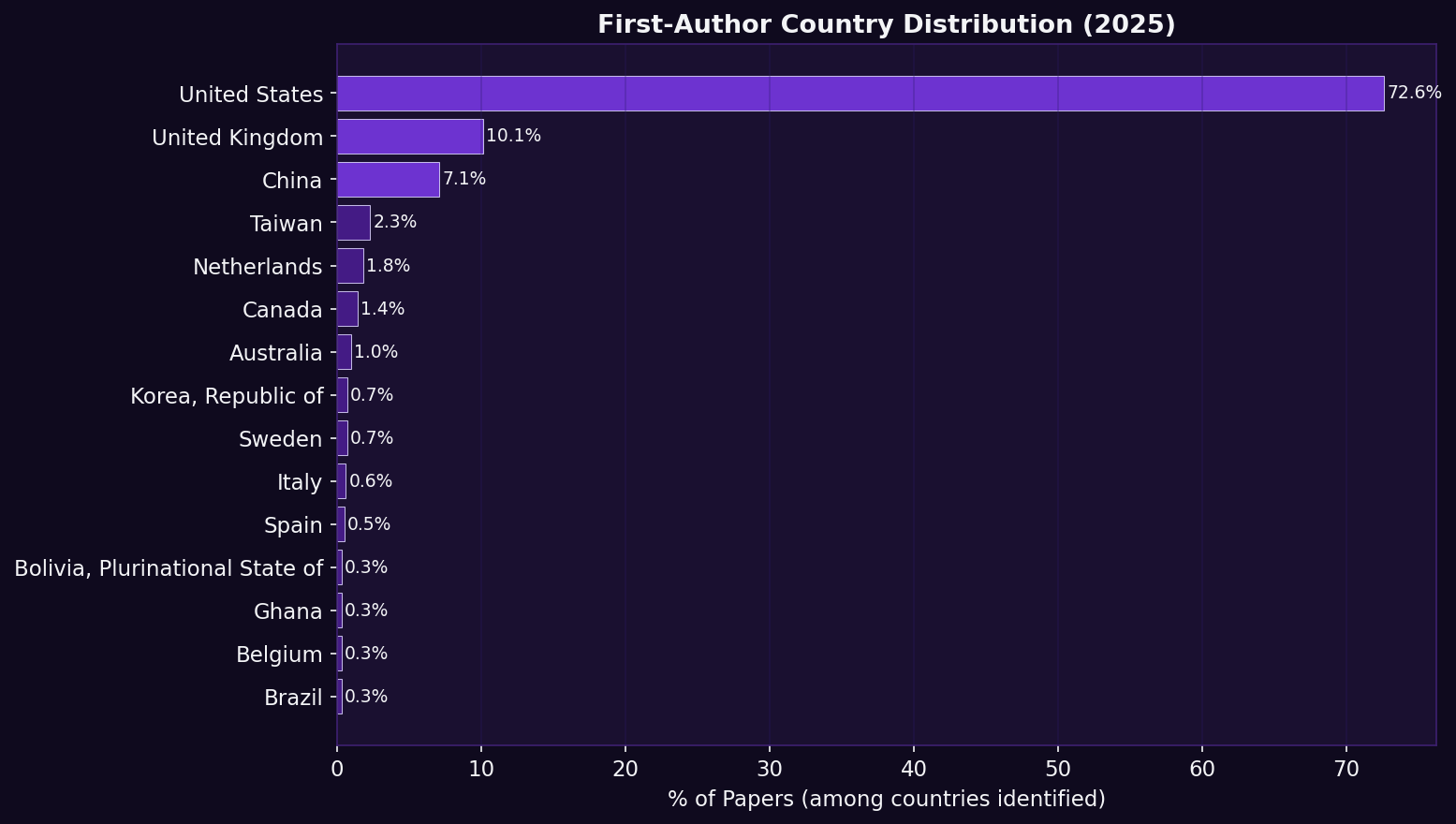
Finding: 905 of 913 papers (99.1%) were successfully attributed to a first-author country. The distribution reveals strong concentration in North America and Europe, with minimal representation from Latin America, Africa, and South/Southeast Asia, the regions facing the fastest-growing dementia burden.
Why this matters: The geographic origin of research teams shapes which questions are asked, which populations are recruited, and what counts as a priority. Researchers embedded in affected regions bring community trust and context-specific expertise that external teams cannot replicate. This figure maps the current baseline of geographic equity in AD research leadership.
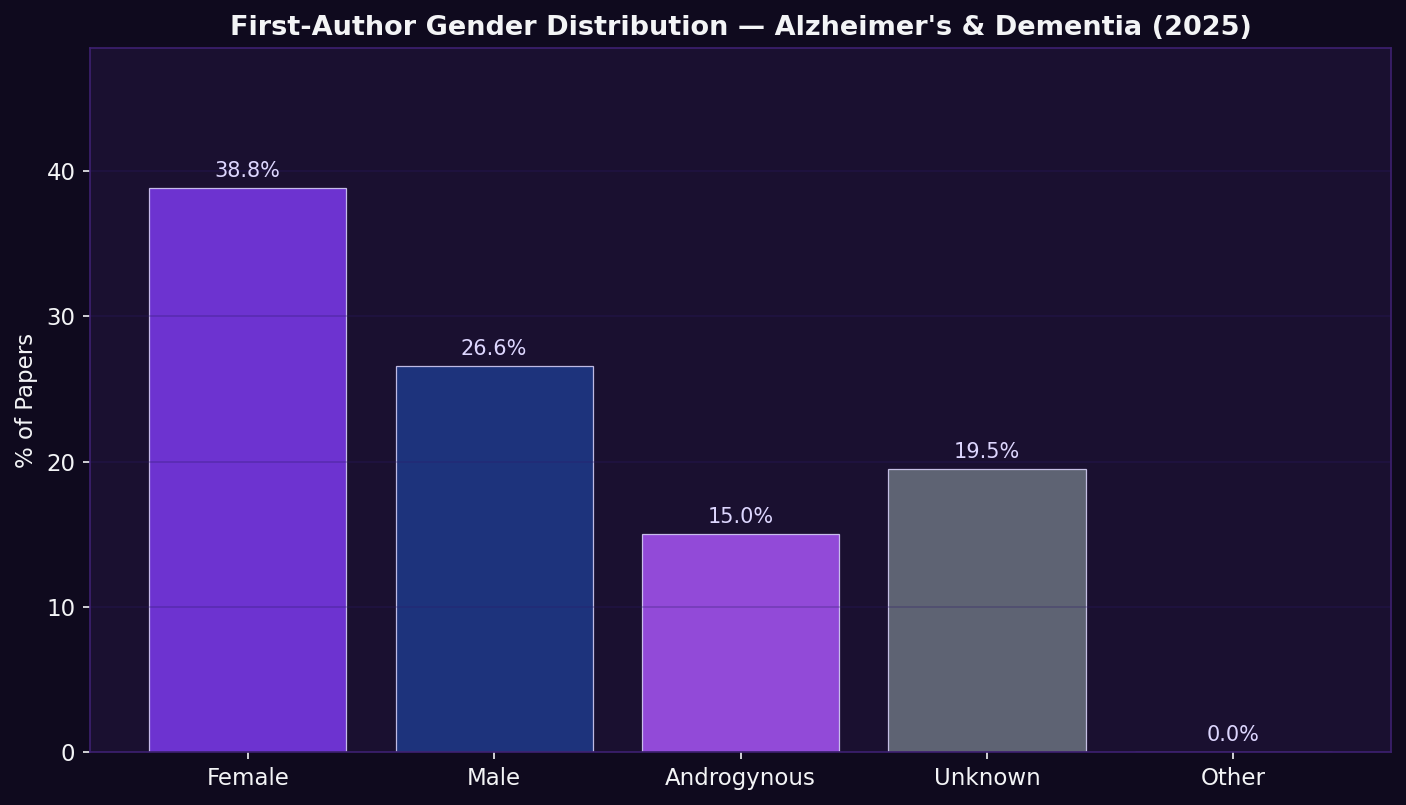
Finding: Distribution of inferred first-author gender across 913 papers (2025), derived from name-based inference. Reflects who is entering and publishing in the AD research pipeline.
Why this matters: Women researchers are more likely to include sex-stratified analyses and to prioritise diversity-focused questions. First-author gender tracks whether the research pipeline is broadening, and whether gender diversity in the workforce translates into methodological diversity in the literature.
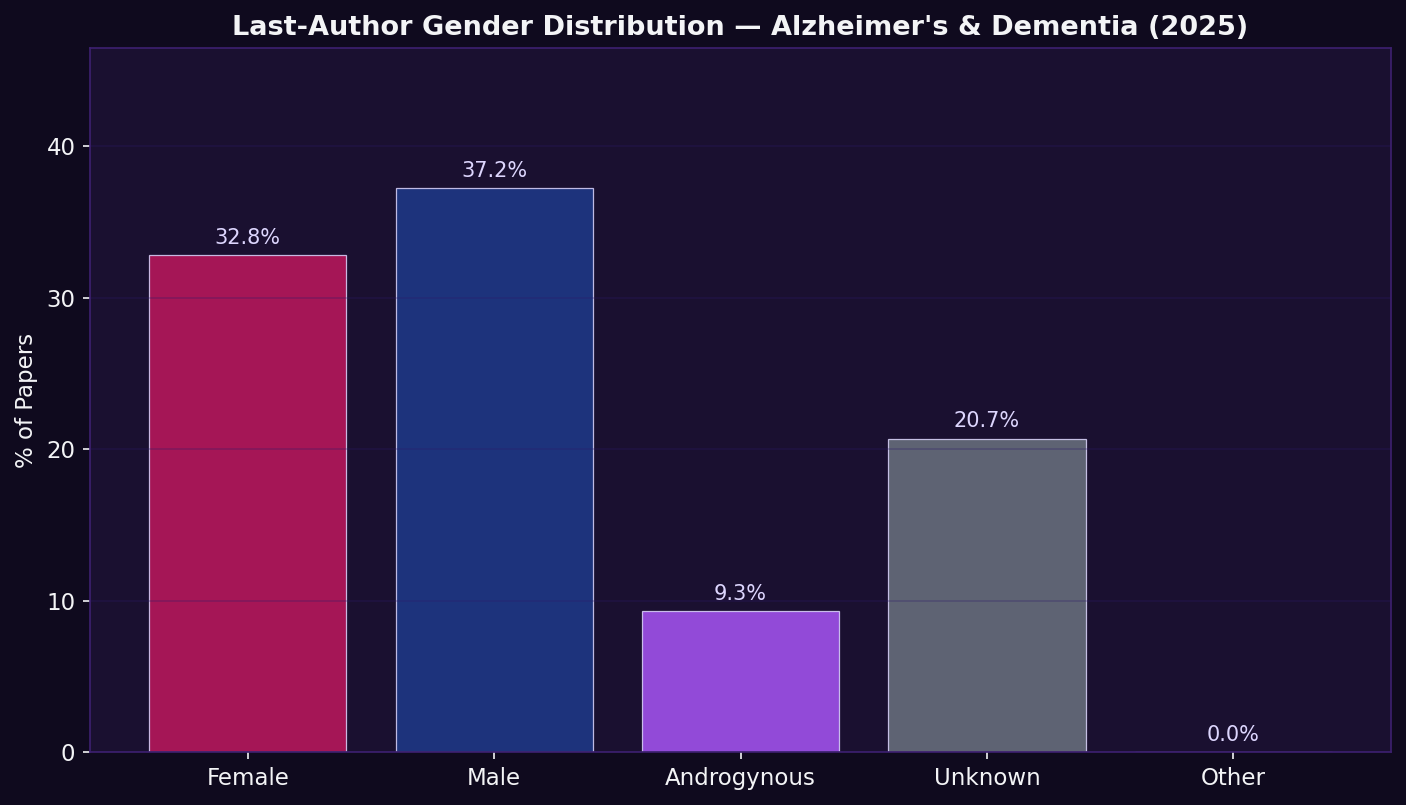
Finding: Distribution of inferred last-author gender, reflecting research leadership (principal investigator positions). Comparing first- vs. last-author distributions reveals whether gender imbalances are concentrated at the senior level.
Why this matters: Senior researchers set agendas, secure funding, and decide what populations to study. Gender diversity at this level is a structural predictor of whether sex-disaggregated and diversity-oriented research will be systematically prioritised, the leadership complement to the biological gap quantified in Pillar II.
DISCLAIMER: Scope and limitations
This analysis is intentionally narrow but reproducible, transparent, and extendable: the pipeline can be applied to any journal, any year, and any keyword set.
A living investigation
Version 1.0 · 2025 · Open to contribution
This is a first investigation, designed to be deepened, extended, and continued over time, tracking how open-science practices and researcher diversity in AD research evolve year by year. It is also meant to be participative. If something seems incorrect, could be improved, or if you have data, datasets, or perspectives to contribute, your input is welcome.
Future directions include extending the audit to other years and journals, adding intra-country ethnic diversity detection, incorporating citation network analysis, and expanding the dataset catalogue with community contributions.
Give feedback